
Le marché de la data science connaît actuellement une explosion de la demande en machine learning, dans tous les secteurs, parfois même jusqu’à l’excès ! Et la tendance n’épargne pas le développement et l’application des algorithmes dans le domaine de la prévision des ventes.
Alors certes, nous direz-vous, la percée des modèles de machine learning de plus en plus performants, est incontestable ces toutes dernières années. Mais il convient toutefois de conserver une distance de sécurité quant aux sirènes du marketing … aussi attractives soient-elles !
En effet, comprendre le périmètre et les limites de l’approche, savoir y faire appel en fonction des réels besoins ainsi que des capacités de l’entreprise, et être capable de l’interpréter, constituent autant de conditions intrinsèques à sa valeur ajoutée.
Le point de vue et les préconisations de Colibri …
Historique du Machine Learning dans les algorithmes de prévision des ventes
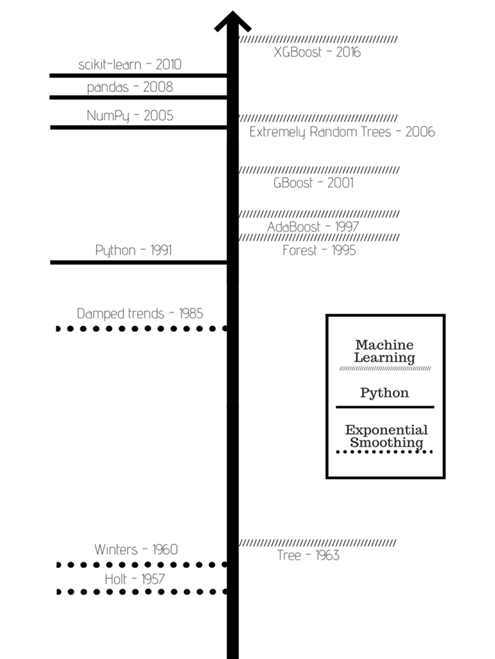
Les techniques de machine learning et plus globalement l’intelligence artificielle sont présentées comme révolutionnaires et suscitent une frénésie démesurée. Or il faut savoir que le machine learning a été inventé dans les années 50 et 60, et s’est développé rapidement à partir des années 80 avant de devenir si populaire. Son utilisation dans le domaine des prévisions date lui aussi des années 60 (arbres de décision), et a progressé sensiblement dans les années 90.
En effet, depuis les années soixante, des modèles traditionnels performants ont fait leurs preuves, qu’il s’agisse des classes de lissage simple, double, triple, exponentiel ou autorégressif. Ils sont parfaitement adaptés aux historiques de ventes réguliers et suffisamment longs. Pour répondre aux demandes intermittentes ou erratiques (par exemple les pièces de rechange) le modèle de Croston a été développé dans les années 70. Ces méthodes dites classiques ont dans la plupart des cas été les plus fiables jusqu’à il y a encore une toute petite poignée d’années, et sont encore souvent les plus performantes sur des historiques réguliers.
Ce n’est qu’à partir de 2016, avec la maturité des techniques de Gradient boosting appliqué aux problématiques de régression, que le machine learning est parvenu à être réguièrement au niveau de performance des méthodes traditionnelles. Un phénomène favorisé par l’essor et la démocratisation des nouvelles technologies, l’accès facilité aux plateformes Cloud intégrant des volumes de données très importants, et la puissance de calcul accrue des machines.
Une porte ouverte à de nombreux concepts … qui explique la percée du machine learning depuis le début des années 2020, et l’engouement qui l’accompagne !

Evolutions récentes du Machine Learning
Depuis 1982, les Makridakis Competitions mettent en concurrence des centaines de chercheurs du monde entier, dans le but de détecter les avancées scientifiques notoires en matière de prévision des ventes … aucun modèle classique n’ayant été détrôné en près de 40 ans. A ce titre d’ailleurs, la récente édition de 2020, a vu les dix-sept méthodes de machine learning, se révéler d’une fiabilité moindre que celle de la méthode étalon Naive … échec cuisant donc.
Pourtant en seulement un an, la tendance s’est drastiquement inversée, avec l’apparition de nouveaux modèles d’apprentissage automatique, dépassant alors haut la main tous les autres. Leur particularité ? Une capacité à intégrer des données additionnelles (features) en tant que variables explicatives et des techniques pour éviter l’écueil du surapprentissage. Pour la prévision des ventes en grande distribution, il s’agit par exemple du prix, de l’historique, des périodes de promotions, des dates de ruptures ou encore des canaux de distribution. La qualité plus que le nombre et la pertinence de ces données, permet d’enrichir le modèle, et d’accroître toujours plus la précision et la fiabilité des résultats.
Depuis 2021, on assiste donc à une véritable course autour des techniques de machine learning : mobilisation massive de la communauté scientifique, compétitions, puissance volumétrique et calculatoire accrue des machines … Les modèles de machine learning intégrant des features s’améliorent ainsi rapidement en termes de temps de calcul et de cohérence, parvenant à supplanter régulièrement les modèles classiques. Prometteur !
Il existe cependant des contreparties non négligeables à ces nouveaux modèles. Très consommateurs de ressources et plus sujets au sur-apprentissage, ils nécessitent un nombre important de données « propres et bien structurées » … avec le risque de dégrader les résultats du modèle si des données non pertinentes sont introduites. Ils se révèlent donc légèrement moins robustes que les modèles traditionnels, plus instables, et peuvent aussi perdre en explicabilité.
Contrairement aux techniques traditionnelles qui peuvent être utilisées « sur étagère », les techniques de machine learning plus avancées nécessitent une phase d’analyse et de configuration par des spécialistes pour être réellement performantes.
Aussi, il est crucial d’être suffisamment éclairé sur le sujet afin d’éviter de se laisser emporter par les éventuelles dérives de l’enthousiasme ambiant.
Machine Learning pour la prévision des ventes : comment bien démarrer avec Colibri ?
Il s’agit avant tout d’éviter de « faire du machine learning pour faire du machine learning ». Oui, même au risque de se voir qualifier de « has been ». Vouloir brûler les étapes s’avèrerait de fait contre productif.
En tant que sage contrepied à l’appel de la mode, le bon sens indique de commencer de manière simple, en effectuant des prévisions à l’aide d’un outil permettant de réaliser des modèles classiques. C’est d’autant plus vrai pour des entreprises n’ayant pas en main les moyens pour traiter des problématiques complexes et impliquant un nombre important de données. Et s’il est légitime de viser le machine learning à terme, poser les bases de son projet à travers un travail méthodologique amont est crucial.
A ce titre, Colibri articule son accompagnement des entreprises autour des axes suivants :
1– Evaluation de l’éligibilité au machine learning selon l’activité, la typologie et la taille de l’entreprise et les bénéfices qu’on peut en attendre.
2-Standardisation des processus et compréhension des besoins métiers
3-Maîtrise de la data : données propres, bien segmentées et de qualité dont les structures doivent être bien comprises et optimisées.
4-Détermination d’objectifs clairs
Une fois le modèle de machine learning mis en place, Colibri s’attache à rendre explicites et intelligibles aux utilisateurs finaux, des résultats issus de modèles complexes. Cette compréhension constitue non seulement un vecteur de confiance et d’adhésion mais elle permet également de piloter le contrôle de la pertinence du modèle en fonction de son contexte (validité des hypothèses, mise à jour des algorithmes en fonction des variables, …)
Le machine learning ne bénéficie pas à tous de manière identique et dans les mêmes proportions. Il ne présente d’ailleurs un intérêt que si le modèle correspond en tous points au métier visé. Entre l’utilisation de modèles simples et accessibles dans Excel et le recours intensif aux modèles basés sur des réseaux neuronaux très prometteurs, il existe une multitude de nuances. Le secret de la réussite ? Réaliser un important et minutieux effort de travail sur la data, savoir faire preuve de mesure, de pragmatisme et avancer progressivement … tout en étant bien accompagné !






